Chapter 1 Introducción a la Analítica de Datos de Pérdida
Resumen del capítulo. Este libro presenta los métodos de análisis de datos de seguros. La sección 1.1 comienza con una discusión de por qué el uso de datos es importante en la industria de seguros. La sección 1.2 ofrece una descripción general de los objetivos en el análisis de datos de seguros, que se complementa con estudio de un caso en la Sección 1.3. Naturalmente, existe una gran distancia entre los objetivos generales resumidos en la descripción general y la aplicación a un caso de estudio concreto; esta distancia se cubre mediante los métodos y técnicas de análisis de datos que se tratan en el resto del texto.
1.1 Relevancia de la Analítica para las Actividades de Seguros
En esta sección, se aprende a:
- Resumir la importancia de los seguros para los consumidores y la economía.
- Describir la analítica de datos.
- Identificar cómo se generan los datos a lo largo de la vida de un contrato de seguro estándar.
1.1.1 Naturaleza y relevancia del seguro
Este libro presenta un proceso que consiste en usar datos para tomar decisiones en el contexto de los seguros. No se asume que los lectores estén familiarizados con los seguros, e introduce los conceptos de seguros según va siendo necesario. Si el lector es nuevo en el mundo de los seguros, probablemente lo más fácil es pensar en una póliza de seguro que cubra el contenido de un apartamento o casa que en el que se vive en alquiler (conocido como el seguro de inquilinos) o el contenido y propiedad de un edificio del que un amigo o uno mismo es el propietario (conocido como el seguro de propietarios). Otro ejemplo muy habitual es el seguro de automóvil. En caso de accidente, esta póliza puede cubrir daños al vehículo, daños a otros vehículos involucrados en el accidente, así como los gastos médicos de los heridos en el accidente.
Una forma de pensar en la naturaleza del seguro es centrarse en quién lo contrata. Los seguros para inquilinos, propietarios de viviendas y automóviles son ejemplos de seguro personal en el sentido de que se trata de pólizas emitidas a personas. Las empresas también contratan seguros, como la cobertura de sus propiedades, y esto se conoce como seguro comercial. El vendedor, la compañía de seguros, también se conoce como aseguradora. Incluso las propias compañías de seguros necesitan un seguro; esto se conoce como reaseguro.
Otra forma de pensar sobre la naturaleza del seguro es centrarse en el tipo de riesgo que se cubre. En los EE. UU., las pólizas como las de inquilinos y propietarios de viviendas se conocen como un seguro de propiedad mientras que una póliza como la de automóvil que cubre los daños a las personas se conocen como un seguro de accidentes. En el resto del mundo, ambos se conocen como seguros de no vida o seguros generales, para distinguirlos del seguro de vida.
Tanto los seguros de vida como los seguros de no vida son componentes importantes de la economía mundial. El Insurance Information Institute (2016) estima que las primas de seguros directos en el mundo en 2014 fueron de 2.654.549 en vida y 2.123.699 no-vida; estas cifras son en millones de dólares estadounidenses y el total representa el 6,2% del PIB mundial. Dicho de otra manera, los seguros de vida representan el 55,5% de las primas y el 3,4% del PIB mundial, mientras que los de no vida representan el 44,5% de las primas de seguros y el 2,8% del PIB mundial. Tanto vida como no-vida representan actividades económicas importantes.
El seguro puede que no sea tan entretenido como la industria del deporte (otra industria que depende en gran medida de los datos) pero afecta a los medios de subsistencia financiera de muchos. Se mire como se mire, los seguros son una actividad económica importante. A nivel mundial, como ya se ha dicho antes, las primas de seguros representaron aproximadamente el 6,2% del PIB en 2014, (Insurance Information Institute 2016). Por ejemplo, las primas de los seguros representaron el 18,9% del PIB en Taiwán (el porcentaje más alto en el estudio) y el 7,3% del PIB en los Estados Unidos. A nivel personal, casi todos los propietarios de una casa tienen un seguro para protegerse en caso de incendio, tormenta de granizo o algún otro episodio catastrófico. En casi todos los países del mundo se exige un seguro para quienes conducen un automóvil. En resumen, aunque no sea un campo particularmente entretenido, el seguro juega un papel importante en las economías de las naciones y en la vida de las personas.
1.1.2 ¿Qué es la Analítica de datos (según su nombre en inglés, Analytics)?
Los seguros son una industria basada en datos. Como todas las grandes corporaciones y organizaciones, las aseguradoras usan datos cuando intentan decidir cuánto pagar a los empleados, cuántos empleados retener, cómo comercializar sus servicios y productos, cómo pronosticar tendencias financieras, etc. Los daos que se usan para esta finalidad representan áreas generales de actividades que no son específicas de la industria de seguros. Aunque cada sector tiene sus propios matices y necesidades de datos, la recopilación, análisis y uso de datos es una actividad compartida por todos, desde los gigantes de Internet hasta la pequeña empresa, pasando por organizaciones públicas y gubernamentales, y, por lo tanto no es una tarea específica de la industria de seguros. En este texto se muestra cómo los métodos y herramientas de recopilación y análisis de datos son relevantes para todos.
En cualquier industria basada en datos, la analítica es clave para derivar y extraer información de los datos. Pero, ¿qué es la analítica? El concepto relacionado con la toma de decisiones empresariales en base a los datos se han descrito como analítica de negocios (en inglés business analytics), inteligencia empresarial (en inglés business intelligence) y ciencia de datos. Estos términos, entre otros, a veces se usan indistintamente y, a veces, se refieren a distintas aplicaciones. La inteligencia empresarial se centra en los procesos de recopilación de datos, a menudo a través de bases de datos, mientras que la analítica de negocios utiliza herramientas y métodos para el análisis estadístico de datos. A diferencia de estos dos términos que enfatizan las aplicaciones empresariales, el término ciencia de datos abarca aplicaciones más amplias relacionadas con los datos en muchos dominios científicos.
Para nuestros propósitos, usamos el término analítica (en inglés analytics) para referirnos al proceso de uso de datos para tomar decisiones. Este proceso implica la recopilación de datos, la comprensión de conceptos y modelos de incertidumbre, la realización de inferencias generales y la comunicación de resultados.
Al introducir los métodos de análisis de datos en este texto, nos centraremos en medir y analizar las pérdidas que surgen de, o están relacionadas con, obligaciones en los contratos de seguro. Esto podría ser la cantidad de daño que ha sufrido un apartamento sujeto a un contrato de seguro de inquilino, la cantidad necesaria para compensar a alguien que sufrió una lesión en un accidente de conducción, y ejemplos por el estilo. A estas obligaciones las llamamos siniestro asegurado. Con este enfoque, podremos introducir y utilizar directamente herramientas y técnicas estadísticas de aplicación general.
1.1.3 Procesos en los seguros
Sin embargo, otra forma de pensar acerca de la naturaleza del seguro es por la duración de un contrato de seguro, conocido como su periodo de cobertura. Este texto se centrará en los contratos de seguro a corto plazo. Por corto plazo, nos referimos a contratos en los que la cobertura de seguro se proporciona normalmente durante un año o seis meses. La mayoría de los contratos comerciales y personales son por un año, por lo que esta será nuestra duración predeterminada. Una excepción importante son las pólizas de automóviles de EE.UU. que suelen tener una duración de seis meses. Por el contrario, normalmente pensamos en el seguro de vida como un contrato donde por defecto se tiene un contrato que dura varios años. Por ejemplo, si una persona de 25 años contrata una póliza de vida que indemniza al fallecer el asegurado y esa persona no muere hasta los 100 años, entonces el contrato tiene una vigencia de 75 años.
Hay otras diferencias importantes entre productos de vida y no vida. En los seguros de vida, la cuantía a pagar al beneficiario a menudo se estipula en las disposiciones del contrato. Por el contrario, la mayoría de los contratos de no-vida proporcionan cobertura para la indemnización de los daños asegurados que se desconocen antes de que ocurra el accidente. (Por lo general, se imponen límites a la cuantía máxima de la compensación.) En un contrato de seguro de vida que se extiende a lo largo de muchos años, el valor del dinero a lo largo del tiempo juega un papel destacado. En cambio, en un contrato de no-vida, la aleatoriedad en la cantidad a indemnizar es primordial.
Tanto en los seguros de vida como en los seguros no-vida, la frecuencia de las reclamaciones por siniestros es muy importante. Para muchos contratos de seguro de vida, el evento asegurado (como el fallecimiento) ocurre solo una vez. Por el contrario, para los seguros no-vida como el de automóviles, es habitual que los individuos (especialmente los conductores jóvenes varones) tengan más de un accidente durante un año. Entonces, nuestros modelos necesitan reflejar esta condición; presentaremos diferentes modelos de frecuencia que también puede usarse también al estudiar algunos seguros de vida.
Para los seguros a corto plazo, el marco del modelo probabilístico es simple. Pensamos en un modelo de un período (la duración del período, por ejemplo, igual a un año, se especificará en cada situación).
- Al comienzo del período, el asegurado paga al asegurador una cantidad conocida como prima acordada por ambas partes del contrato.
- Al final del período, el asegurador reembolsa al asegurado una (posiblemente multivariante) pérdida aleatoria.
Este marco se desarrollará a medida que avancemos; pero primero nos centramos en analizar cómo se generan los datos en este contexto. Desde el punto de vista de una aseguradora, los contratos pueden ser solo por un año, pero tienden a renovarse. Además, los pagos derivados de reclamaciones durante el año pueden retrasarse mucho más allá de un solo año. Una forma de describir los datos que surgen de las operaciones de una compañía de seguros es utilizar un enfoque granular de cronograma. Un enfoque de proceso proporciona una visión general de los sucesos que ocurren durante la vida de un contrato de seguro y su naturaleza: sucesos aleatorios o planificados, siniestros (reclamaciones) y sucesos de cambios de contrato, etc. En esta visión micro orientada, podemos pensar en lo que le sucede a un contrato en varias etapas de su existencia.
La figura 1.1 traza una línea de tiempo de un contrato de seguro estándar. Durante la vigencia del contrato, la aseguradora procesa periódicamente sucesos como el cobro de primas y la valoración, descritas en la Sección 1.2; estas están marcados con una x en la línea de tiempo. También ocurren sucesos no regulares e imprevistos. Para ilustrar, \(\mathrm{t}_2\) y \(\mathrm{t}_4\) marcan la ocurrencia de un siniestro (algunos contratos, como los seguros de vida, pueden tener un único siniestro). Los instantes \(\mathrm{t}_3\) y \(\mathrm{t}_5\) marcan momentos en los que un asegurado desea alterar ciertas características de su contrato, como la elección de una franquicia o la cantidad de cobertura. Desde la perspectiva de una empresa aseguradora, incluso se puede pensar en el inicio del contrato (llegada, en el momento \(\mathrm{t}_1\)) y finalización del contrato (salida, en el momento \(\mathrm{t}_6\)) como eventos inciertos. (Alternativamente, para algunos propósitos, se puede condicionar a estos eventos y tratarlos como ciertos).

Figure 1.1: Cronograma de una póliza de seguro estándar. Las flechas marcan las ocurrencias de eventos aleatorios. Cada x marca el instante de los eventos programados que normalmente no son aleatorios.
1.2 Operaciones de la Compañía de Seguros
En esta sección, se aprenderá a:
- Describir cinco áreas operativas principales de las compañías de seguros.
- Identificar el papel de las oportunidades que aportan los datos y la analítica dentro de cada área operativa.
Usando los datos de seguros, el objetivo final es utilizar los datos para tomar decisiones. Aprenderemos más sobre métodos de análisis y extrapolación de datos en capítulos futuros. Para empezar, pensemos por qué queremos hacer el análisis. Tomaremos el punto de vista de la compañía de seguros (no el de la persona asegurada) e introduciremos formas de cobrar dinero, pagarlo, administrar los costes y asegurarnos de que tengamos suficiente capital para cumplir con las obligaciones de un asegurador. El énfasis está en las operaciones específicas de seguros más que en las actividades comerciales generales como la publicidad, el marketing y la gestión de recursos humanos.
Específicamente, en muchas compañías de seguros, se acostumbra a agregar los procesos de seguros concretos en unidades operativas más grandes; muchas empresas utilizan varias áreas funcionales para segregar las actividades de los empleados y sus áreas de responsabilidad. Los actuarios, otros analistas financieros y los reguladores de seguros trabajan dentro de estas unidades y utilizan datos para las siguientes actividades:
- Inicio del seguro. En esta etapa, la empresa toma una decisión sobre si debe asumir o no un riesgo (la etapa de suscripción) y asigna una prima (o tarifa). El análisis de seguros tiene sus raíces actuariales en la elaboración de tarifas, donde los analistas buscan determinar el precio correcto por el riesgo correcto.
- Renovación del seguro. Muchos contratos, particularmente en seguros generales, tienen duraciones relativamente cortas, como 6 meses o un año. Aunque existe una expectativa implícita de que todos los contratos se renovarán, el asegurador tiene la oportunidad de rechazar la cobertura y ajustar la prima. También se utiliza la analítica en esta etapa de renovación de la póliza donde el objetivo es retener a los clientes rentables.
- Gestión de siniestros. La analítica de datos se ha utilizado durante mucho tiempo para (1) detectar y prevenir el fraude en las reclamaciones sinestros, (2) administrar los costes de los siniestros, incluyendo el identificar el soporte adecuado para los gastos de tramitación de siniestros, así como (3) comprender los tramos de exceso de coste para fijar la retención y el reaseguro.
- Reserva de pérdidas. Las herramientas analíticas se utilizan para proporcionar a los gestores una estimación adecuada de las obligaciones futuras y para cuantificar la incertidumbre de esas estimaciones.
- Solvencia y Asignación de Capital. Decidir sobre el requisito de cantidad de capital y sobre las formas de asignar capital entre las inversiones alternativas también son actividades analíticas esenciales. Las empresas deben evaluar cuánto capital es necesario para tener un flujo de efectivo disponible suficiente para cumplir con sus obligaciones cuando llegue el momento de que se materialicen (solvencia). Esta es una pregunta importante que concierne no solo a los gerentes de la empresa, sino también a los clientes, los accionistas de la empresa, las autoridades reguladoras, así como a la sociedad en general. Relacionado con la cuestión de cuánto capital es necesario, hay que abordar la cuestión de cómo asignar ese capital a los diferentes proyectos financieros, por lo general para maximizar un retorno de la inversión. Aunque esta pregunta puede surgir a varios niveles, las compañías de seguros generalmente se preocupan por cómo asignar capital a sus diferentes líneas de negocio dentro de la empresa y a diferentes filiales de una misma empresa matriz.
Aunque los datos representan un componente crítico para el cálculo del capital de solvencia y la asignación, otros componentes, incluido el marco económico local y global, el entorno de inversiones financieras y los requisitos específicos fijados por el entorno regulatorio del momento, también son importantes. Debido a los conocimientos previos requeridos para abordar estos temas, no abordaremos cuestiones de solvencia, asignación de capital y regulación en este texto.
No obstante, para todas las funciones operativas, enfatizamos que la analítica en la industria de seguros no es un ejercicio que un pequeño grupo de analistas pueden hacer por sí mismos. Requiere que una aseguradora realice importantes inversiones en tecnología de la información, marketing, suscripción, y funciones actuariales. Como estas áreas representan los principales objetivos finales del análisis de datos, en las siguientes subsecciones se presentan los antecedentes adicionales de cada unidad operativa.
1.2.1 Inicio del seguro
Fijar el precio de un producto de seguro puede ser un problema desconcertante. Ello contrasta con otras industrias, como la fabricación, donde el coste de un producto es (relativamente) conocido y proporciona un punto de referencia para evaluar un precio de demanda del mercado. De manera similar, en otras áreas de servicios financieros, los precios de mercado están disponibles y proporcionan la base para una estructura de precios de productos coherente con el mercado. Sin embargo, para muchas líneas de seguros, el coste de un producto es incierto y los precios de mercado no están disponibles. La esperanza del coste aleatorio es un razonable punto de partida para fijar un precio. (Si se ha estudiado finanzas, se recordará que una esperanza es el precio óptimo para una aseguradora neutral al riesgo). Ha sido tradicional en la fijación de precios de seguros empezar siempre con el coste esperado. Las aseguradoras luego agregan márgenes a este coste esperado, para tener en cuenta el riesgo del producto, los gastos incurridos en el mantenimiento del producto y una provisión para beneficios/excedentes de la empresa.
El uso de los costes esperados como base para la fijación de precios prevalece en algunas líneas del negocio de seguros como los seguros para propietarios de viviendas y los seguros de automóviles. Para estas tipologías, la analítica ha servido para mejora el precio que llega al mercado al hacer que el cálculo del coste esperado del producto sea más preciso. La creciente disponibilidad de Internet por parte de los consumidores también ha servido para aumentar la transparencia en los precios. En el mercado actual, los consumidores tienen fácil acceso a los precios ofertados por una gran cantidad de aseguradoras. Las aseguradoras buscan aumentar su cuota de mercado mediante el perfeccionamiento de sus sistemas de clasificación de riesgo, logrando así una mejor aproximación de precios en determinados productos y permitiendo estrategias de suscripción de los clientes óptimos (“cream-skimming” es una frase que se utiliza cuando la aseguradora suscribe solo los mejores riesgos). Algunas encuestas recientes (por ejemplo, Earnix (2013)) indican que la fijación de precios es el área donde más se usa la analítica en las aseguradoras.
Suscripción, el proceso de clasificación de riesgos en categorías homogéneas y la asignación de asegurados a esas categorías, se encuentra en el núcleo de la elaboración de tarifas. Los asegurados de cada una de las clases (categorías) tienen un perfil de riesgo similar y, por lo tanto, se les cobra un mismo precio por el seguro que suscriben. Este es el concepto de prima actuarialmente justa; es justo cobrar tarifas diferentes si los asegurados muestran diferencias identificables en los factores de riesgo. En un artículo pionero, Two Studies in Automobile Insurance Ratemaking (Bailey and LeRoy 1960) proporcionó un catalizador para la aceptación de métodos analíticos en el sector de los seguros. Este trabajo abordaba el problema de la clasificación en tarificación. Describía un ejemplo de seguro de automóvil con cinco clases de clasificación cruzada por uso y cuatro tipos de bonificación relacionados con el mérito del asegurado. Hasta ese momento, la dependencia de las primas por uso y tipo de bonificación se determinaban por separado. Tener en cuenta la interacción de los efectos de las diferentes variables de clasificación es un problema más difícil de resolver.
1.2.2 Renovación del seguro
El seguro es un tipo de servicio financiero y, como muchos otros servicios o contratos, la cobertura del seguro a menudo se acuerda por un tiempo limitado, cuyo transcurso marca la finalización del compromiso de proporcionar cobertura. En particular para los seguros generales, la necesidad de cobertura continúa, por lo que se hace un esfuerzo para emitir un nuevo contrato que brinde una cobertura similar, cuando el contrato existente llega al final de su vigencia. A esto se le llama renovación de la póliza. También puede surgir la necesidad de renovación de las pólizas en los seguros de vida, por ejemplo, en el seguro de vida temporal. No sucede lo mismo en otros contratos, como en el seguro de rentas vitalicias, que termina con el fallecimiento del asegurado y, por lo tanto, en el que la cuestiones relativas a la renovación son irrelevantes.
En ausencia de restricciones legales, en la renovación, el asegurador tiene la oportunidad de:
- aceptar o negarse a suscribir el riesgo; y
- determinar una nueva prima, posiblemente junto con una nueva clasificación del riesgo.
La clasificación y tarificación del riesgo en el momento de la renovación se basa en dos tipos de información. Primero, en la etapa inicial, el asegurador tiene muchas variables de calificación disponibles para poder tomar una decisión. Muchas variables no cambiarán posteriormente, por ejemplo el sexo, mientras que es probable que otras cambien, por ejemplo la edad, y otras pueden cambiar o no, por ejemplo, la valoración crediticia. En segundo lugar, a diferencia de la etapa inicial, en la renovación, el asegurador tiene a su disposición un historial de la experiencia de las pérdidas sufridas por el titular de la póliza, y este historial puede proporcionar información sobre el asegurado que no estaba disponible en la tarificación mediante las variables iniciales. La modificación de primas con historial de siniestros se conoce como tarificación basada en la experiencia, también conocida como tarificación por méritos.
Los métodos de tarificación basada en la experiencia se aplican retrospectivamente o prospectivamente. Con los métodos retrospectivos, se proporciona al tomador de la póliza un reembolso de una parte de la prima si se dan de ciertas condiciones de experiencia favorable (para la aseguradora). Las primas retrospectivas son habituales en los acuerdos de seguros de vida (donde los asegurados ganan dividendos en los EE. UU., bonificaciones en el Reino Unido y participación en las ganancias en la cobertura de vida temporal en Israel). En los seguros generales, los métodos prospectivos son más frecuentes, y se recompensa la experiencia favorable del asegurado a través de una prima de renovación más baja.
El historial de siniestralidad puede proporcionar información sobre el apetito al riesgo del asegurado. Por ejemplo, en líneas personales se suele usar una variable para indicar si se ha producido o no un siniestro en los últimos tres años. Otro ejemplo es el de una línea comercial como el seguro de empleo u ocupación, en el que se puede observar la frecuencia o gravedad promedio de las reclamaciones de siniestros de un asegurado durante los últimos tres años. El historial de siniestros puede revelar información que de otro modo estaría oculta (para la aseguradora) sobre el titular de la póliza.
1.2.3 Gestión de productos y siniestros
En algunas áreas de los seguros, el proceso de pago de reclamaciones para los siniestros que están cubiertos es relativamente sencillo. Por ejemplo, en los seguros de vida, un certificado de defunción simple es todo lo que se necesita para percibir la cuantía que corresponde al beneficiario tal como se estipule en el contrato. Sin embargo, en áreas no relacionadas con la vida como en los seguros de propiedad y accidentes, el proceso puede ser mucho más complejo. Pensemos por ejemplo en un suceso relativamente simple como un accidente de automóvil. Aquí, a menudo se requiere determinar qué parte tiene la culpa del accidente, es necesario evaluar los daños a todos los vehículos y personas involucrados en el siniestro, tanto asegurados como no asegurados, los gastos incurridos en la evaluación de los daños también deben evaluarse, y así sucesivamente. El proceso de determinación de cobertura, responsabilidad legal y resolución de reclamaciones se conoce como tramitación de siniestros.
Los aseguradores a veces usan el concepto de fuga o escape para referirse al dinero perdido en las ineficiencias de la gestión de siniestros. Hay muchas formas en las que la analítica de datos puede ayudar a gestionar el proceso de tramitación, Gorman and Swenson (2013). Históricamente, la tarea más importante ha sido la detección de fraudes. El proceso de tramitación de siniestros implica reducir la asimetría de información (el reclamante sabe lo que pasó; la empresa sabe sólo algo de lo que pasó). Mitigar el fraude es una parte importante del proceso de gestión de siniestros.
La detección de fraudes es solo un aspecto de la gestión de las reclamaciones. En términos más generales, se puede pensar que la gestión de siniestros consta de los siguientes componentes:
Triaje de siniestros. Al igual que en el mundo médico, la identificación precoz y el manejo apropiado de los siniestros de elevada cuantía (pacientes, en el mundo médico), puede conducir a ahorros substanciales. Por ejemplo, en los seguros de empleo, las aseguradoras buscan lograr la identificación temprana de aquellos siniestros que corren el riesgo de incurrir en elevados costes médicos y un largo período de pago. La intervención temprana en estos casos podría dar a las aseguradoras un mayor control sobre la gestión del siniestro, el tratamiento médico y los costes generales para lograr un retorno al trabajo lo más pronto posible.
Tramitación de siniestros. El objetivo es utilizar la analítica para identificar siniestros muy habituales que se prevé que tendrán un coste pequeño. Las situaciones más complejas pueden requerir peritos más experimentados y asistencia legal para manejar adecuadamente las reclamaciones con un coste potencial elevado.
Decisiones de peritaje. Una vez se identifica un siniestro complejo y se asigna a un perito, se pueden establecer rutinas analíticas para ayudar a los procesos posteriores de toma de decisiones. Dichos procesos también pueden ser útiles para los peritos en el cálculo reservas, una estimación de la responsabilidad futura del asegurador. Esta es una información importante para calcular las reservas por pérdidas de la aseguradora, descritas en la Sección 1.2.4.
Además del reembolso de las pérdidas que satisface el asegurador, éste también debe preocuparse por otra fuente de pérdida de ingresos, los gastos. Los gastos de peritaje de las pérdidas son parte del coste de gestión de los siniestros de una aseguradora. La analítica de datos se puede utilizar para reducir gastos directamente relacionados con la gestión de siniestros (asignados) así como el tiempo del personal que en general se usa para supervisar los procesos de gestión de los siniestros (no asignados). El sector asegurador tiene costes operativos elevados en relación con otras organizaciones del sector de los servicios financieros.
Además de los pagos de las reclamaciones, hay muchas otras formas en las que las aseguradoras utilizan datos para gestionar sus productos. Ya hemos discutido la necesidad de analizar la suscripción, es decir, la clasificación de los riesgos en las etapas iniciales de adquisición y renovación. Las aseguradoras también están interesadas en qué tipo de asegurados deciden renovar su contrato y, al igual que con otros productos, están interesadas en monitorizar la fidelidad de sus clientes.
La analítica también se puede utilizar para gestionar una cartera de pólizas o el conjunto de riesgos que ha suscrito una aseguradora. Cuando se presenta inicialmente el riesgo, la aseguradora puede actuar imponiendo parámetros contractuales que modifiquen las condiciones ligadas a los pagos que prevé el contrato. Los capítulos 3 y 10 describen las modificaciones más usuales que incluyen el coaseguro, las franquicias y los límites superiores de la póliza.
Una vez acordados los términos del contrato con un asegurado, el asegurador puede todavía modificar su obligación neta mediante la celebración de un convenio de reaseguro. Este tipo de contrato se realiza con un reasegurador, un asegurador de un asegurador. Es completamente normal que las compañías de seguros adquieran seguros para su cartera de riesgos a fin de obtener protección contra sucesos inusuales, al igual que las personas y otras empresas lo hacen.
1.2.4 Provisiones
Una característica importante que distingue a los seguros de otros sectores de la economía es el momento del intercambio de los bienes. En la industria manufacturera, los pagos por bienes generalmente se realizan en el momento de una transacción. Por el contrario, en el caso de los seguros, el dinero recibido de un cliente se obtiene antes de los beneficios o servicios; estos se concretan en una fecha posterior, en la que ocurre el hecho asegurado. Esto lleva a la necesidad de disponer de una reserva de capital para hacer frente a las obligaciones futuras respecto de las obligaciones asumidas y para ganarse la confianza de los asegurados respecto a que la empresa podrá cumplir con sus compromisos. El tamaño de esta reserva de capital y la importancia de garantizar su adecuación es una de las principales preocupaciones de la industria de seguros.
La reserva de capital para siniestros impagados se conoce como reserva por pérdidas; en algunas jurisdicciones, las reservas también se conocen como provisiones técnicas. En la Figura 1.1 se aprecia las veces en las que una empresa cierra su posición financiera; estos momentos se conocen como fechas de valoración. Los siniestros que se declaran antes de las fechas de valoración normalmente ya se han pagado, están en proceso de pago o están a punto de pagarse; Se desconocen los siniestros que se devengarán tras las fechas de valoración. Una empresa debe estimar estos pasivos pendientes al determinar su solidez financiera. Determinar con precisión las provisiones es importante para las aseguradoras por muchas razones.
- Las provisiones representan una reclamación anticipada que la aseguradora debe a sus clientes. Una provisión insuficiente puede acabar en un incumplimiento de las responsabilidades de la reclamación de un siniestro. Por el contrario, una aseguradora con excesivas provisiones puede presentar una peor posición financiera de la que realmente tiene.
- Las provisiones proporcionan una estimación del coste no pagado del seguro que se pueden utilizar para calcular precios de nuevos contratos.
- Las leyes y regulaciones exigen el establecimiento de provisiones. La sociedad tiene sumo interés en que se pueda garantizar la solidez financiera y la solvencia de las aseguradoras.
- Además de la administración y los reguladores de las compañías de seguros, otras partes interesadas, como inversores y clientes, toman decisiones que dependen de las provisiones que tenga una empresa.
Las provisiones son un área del seguro en la que existen diferencias sustanciales entre los seguros de vida y los seguros generales (también conocido como no-vida). En los seguros de vida, la gravedad (cuantía de la pérdida) a menudo no es una fuente de incertidumbre ya que los pagos a realizar se especifican en el contrato. La frecuencia, determinada por la curva de mortalidad de los asegurados, es lo que preocupa. Sin embargo, debido a la cantidad de tiempo que transcurre hasta la liquidación de los contratos de seguros de vida, el valor temporal de la incertidumbre monetaria medida desde la emisión hasta la fecha de pago puede dominar las preocupaciones sobre la frecuencia. Por ejemplo, para un asegurado que compra un contrato de vida a los 20 años, no sería raro que el contrato siguiera abierto al cabo de 60 años, cuando el asegurado celebrase su 80 cumpleaños. Para más información, ver, por ejemplo, Bowers et al. (1986) o Dickson, Hardy, and Waters (2013) para obtener información sobre cómo reservar un seguro de vida.
1.3 Caso de Estudio: Fondo de Propiedad de Wisconsin
En esta sección, usamos el Fondo de Propiedad de Wisconsin como un caso de estudio. Se aprenderá a:
- Describir cómo los sucesos que generan la información pueden producir datos de interés para los analistas de seguros.
- Producir estadísticas descriptivas relevantes para cada variable.
- Describir cómo se pueden utilizar estos resultados en cada una de las principales áreas operativas de una compañía de seguros.
Ilustremos el tipo de datos bajo consideración y los objetivos que deseamos lograr mediante el análisis de la Local Government Property Insurance Fund (LGPIF), un conjunto de pólizas de seguros administrado por la Oficina del Comisionado de Seguros de Wisconsin. La LGPIF se creó para proporcionar seguros de propiedad para entidades gubernamentales locales que incluían condados, ciudades, pueblos, aldeas, distritos escolares y de bibliotecas. El fondo asegura toda propiedad del gobierno local, como los edificios gubernamentales, las escuelas, las bibliotecas y los vehículos de motor. El fondo cubre toda pérdida que afecta a la propiedad, excepto las que son consecuencia de inundaciones, terremotos, desgaste, temperaturas extremas, moho, guerras, reacciones nucleares y malversación de fondos o robo por parte de un empleado.
El fondo cubre más de mil entidades gubernamentales locales que pagan aproximadamente 25 millones de dólares en primas cada año y reciben una cobertura de seguro de aproximadamente 75 mil millones de dólares. Los edificios del gobierno estatal no están cubiertos; la LGPIF es para entidades del gobierno local que tienen responsabilidades presupuestarias separadas y que necesitan un seguro para moderar los efectos presupuestarios de sucesos asegurables inciertos. La cobertura a la propiedad del gobierno local ha estado vigente en Wisconsin desde 1911, proporcionando así una gran cantidad de datos históricos.
En esta ilustración, restringimos el análisis a los siniestros de la cobertura de los edificios y su contenido; no consideramos siniestros de vehículos motorizados y equipos especializados que son propiedad de las entidades locales (como máquinas quitanieves). También consideramos solo las reclamaciones que están cerradas, con obligaciones totalmente cumplidas.
1.3.1 Variables de siniestralidad del fondo: frecuencia y severidad
Fundamentalmente, las compañías de seguros aceptan primas a cambio de promesas de compensar al asegurado en caso de que ocurra un siniestro contemplado en la póliza. La indemnización es la compensación proporcionada por la aseguradora por los daños, pérdidas o daños incurridos que están cubiertos por la póliza. Esta compensación también se conoce como siniestro. La magnitud de la cuantía del pago, conocido como severidad, es un gasto financiero clave para una aseguradora.
En términos de gasto monetario, a una aseguradora le es indiferente tener diez siniestros de 100 que un siniestro de 1000. No obstante, es habitual que las aseguradoras estudien la frecuencia con la que se producen los siniestros, conocida como la frecuencia de siniestralidad. La frecuencia es importante para calcular los gastos, pero también influye en la determinación de los parámetros contractuales (como la franquicia y los límites de la póliza que se describen más adelante) que se establecen en función de la ocurrencia concreta de cada siniestro y se va controlando periódicamente por el supervisor de los seguros, y puede ser un factor clave en la determinación del compromiso de indemnización global del asegurador. Consideraremos la frecuencia y la severidad como las dos principales variables de siniestralidad que deseamos comprender, modelar y gestionar.
Por ejemplo, en 2010 había 1.110 asegurados en el fondo de propiedad que sufrieron un total de 1.377 siniestros. La tabla 1.1 muestra la distribución. Casi dos tercios (0,637) de los asegurados no tuvieron ningún siniestro y un 18,8% adicional tuvo solo un siniestro. El 17,5% restante (= 1-0,637-0,188) tuvo más de un siniestro; el asegurado con el mayor número de siniestros registró un total de 239. El número medio de siniestros en esta muestra fue 1,24 (= 1377/1110).
| Tipo | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Número | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 o más | Suma |
| Frec. | 707 | 209 | 86 | 40 | 18 | 12 | 9 | 4 | 6 | 19 | 1110 |
| Siniestros | 0 | 209 | 172 | 120 | 72 | 60 | 54 | 28 | 48 | 617 | 1377 |
| Proporción | 0,637 | 0,188 | 0,077 | 0,036 | 0,016 | 0,011 | 0,008 | 0,004 | 0,005 | 0,017 | 1,000 |
Código R para la Tabla de Frecuencias
Para analizar la distribución de la severidad, el enfoque habitual es examinar la distribución de la muestra de los 1.377 siniestros. Sin embargo, otra alternativa consiste en examinar la distribución del promedio de los siniestros de los asegurados que sufrieron algún siniestro. En nuestra muestra de 2010, hubo 403 (= 1110-707) asegurados que sufrieron algún siniestro. Para 209 de dichos asegurados con un solo siniestro, el coste medio es igual al coste del único siniestro que tuvieron. Para el asegurado con mayor frecuencia, el coste medio es un promedio de 239 siniestros declarados por separado. Este promedio también se conoce como la prima pura o coste del siniestro.
La tabla 1.2 resume la distribución de la muestra de las severidades promedio de los 403 asegurados que presentaron una reclamación de siniestro; muestra que el coste medio los siniestros fue igual a 56.330 (todos los costes están expresados en dólares estadounidenses). Sin embargo, el promedio solo da una mirada limitada de la distribución. Se puede extraer más información de los estadísticos descriptivos resumen que muestran un siniestro muy grande con una cuantía igual a 12.920.000. La figura 1.2 proporciona más información sobre la distribución del coste de los siniestros de la muestra, y revela una distribución que está dominada por este único gran siniestro de modo que el histograma no es muy útil. Incluso al eliminar el siniestro elevado, nos encontramos ante una distribución que está sesgada a la derecha. En general, la técnica más aceptada es trabajar con severidades expresadas en unidades logarítmicas, especialmente cuando se analizan gráficos; la figura correspondiente en el panel de la derecha es mucho más fácil de interpretar.
| Mínimo | Primer Cuartil | Mediana | Media | Tercer Cuartil | Máximo |
|---|---|---|---|---|---|
| 167 | 2.226 | 4.951 | 56.330 | 11.900 | 12.920.000 |
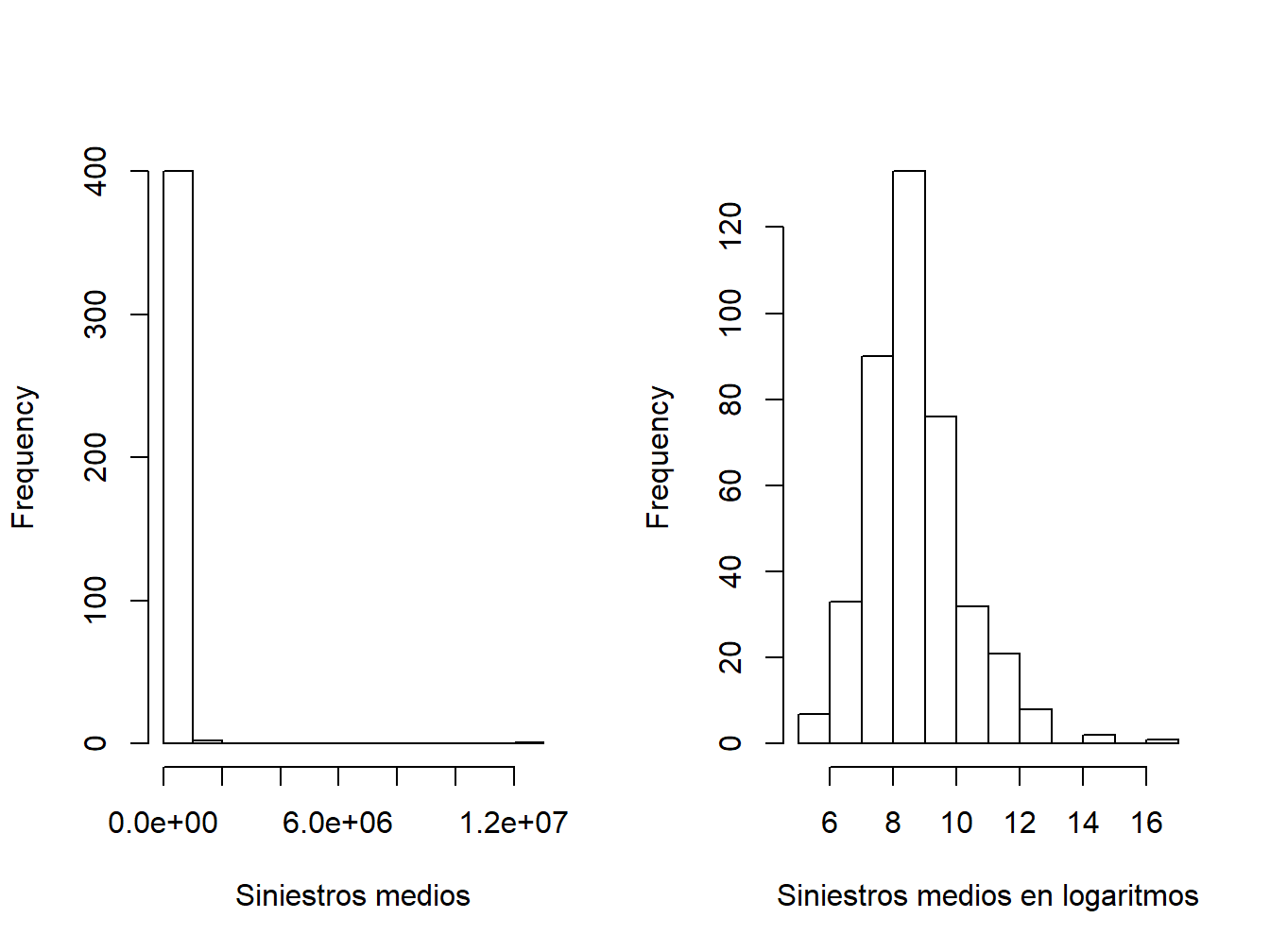
Figure 1.2: Distribución del promedio de severidades positivas
Código R para la Tabla y Figuras de la distribución de la severidad
1.3.2 Variables de clasificación del fondo
El objetivo de los primeros capítulos de este texto es desarrollar modelos para representar y gestionar las dos variables principales en el análisis de la siniestralidad, frecuencia y severidad. Sin embargo, cuando los actuarios y otros analistas financieros utilizan esos modelos, lo hacen usando variables externas. En general, usando terminología estadística, se podría llamar a dichas variables las variables explicativas o predictoras; hay muchos otros nombres en estadística, economía, psicología y otras disciplinas. Debido a nuestro enfoque en seguros, vamos a llamarlas variables de tarificación ya que serán útiles para establecer tarifas y primas de seguros.
Habíamos empezado considerando las observaciones de una muestra de 1.110 asegurados que, en principio, podían parecer muchos. Sin embargo, como veremos en nuestras próximas aplicaciones, debido a la elevada presencia de ceros y a la elevada asimetría en los siniestros, los actuarios normalmente desean tener más datos. Un enfoque muy habitual, que adoptamos aquí, es examinar los resultados de varios años, aumentando así el tamaño de la muestra. Discutiremos las fortalezas y limitaciones de esta estrategia más adelante, pero, de momento, solo vamos a explicar al lector cómo funciona.
Específicamente, la Tabla 1.3 muestra que ahora consideramos pólizas vigentes en cinco años con datos disponibles, 2006, …, 2010, incluido. Los datos comienzan en 2006 porque hubo un cambio en la codificación de los siniestros en 2005, por lo que no es posible realizar comparaciones con años anteriores. Para mitigar el efecto de los siniestros abiertos, sólo consideraremos los años anteriores a 2011. Un siniestro abierto significa que todavía no se conocen todas las obligaciones que implica dicho siniestro en el momento del análisis; para algunos siniestros, como cuando existe una lesión a una persona en un accidente de automóvil o en el lugar de trabajo, se sabe que pueden pasar años antes de que los costes sean completamente conocidos.
| Año | Promedio Frecuenc. | Promedio Severid. | Promedio Coberturas | Número de Asegurados |
|---|---|---|---|---|
| 2006 | 0,951 | 9.695 | 32.498.186 | 1.154 |
| 2007 | 1,167 | 6.544 | 35.275.949 | 1.138 |
| 2008 | 0,974 | 5.311 | 37.267.485 | 1.125 |
| 2009 | 1,219 | 4.572 | 40.355.382 | 1.112 |
| 2010 | 1,241 | 20.452 | 41.242.070 | 1.110 |
Código R para resumen de siniestralidad por póliza
La tabla 1.3 muestra que el siniestro medio varía a lo largo del tiempo, especialmente con un valor alto en el año 2010 (que vimos que estaba provocado por un único siniestro elevado).1 El número total de asegurados va disminuyendo progresivamente y, por el contrario, la cobertura va aumentando. La variable de cobertura es la cantidad de cobertura de la propiedad y de los contenidos. Aproximadamente, se puede entender como el pago máximo posible que podría llegar a pagar el asegurador. Para nuestros propósitos inmediatos, la cobertura es nuestra primera variable de tarificación. En igualdad de condiciones, lo que esperamos es que titulares de pólizas con mayor cobertura tengan siniestros de coste más elevado. Concretaremos mucho más esta idea a medida que avancemos en nuestro análisis, y también justificaremos esta expectativa a través de los datos.
Para tener una visión diferente de los datos de 2006-2010, la table 1.4 resume la distribución de nuestros dos resultados, frecuencia y coste del siniestro. En cada caso, el promedio excede la mediana, lo que sugiere que las dos distribuciones tienen asimetría a la derecha. Además, la table resume nuestras variables continuas de tarificación, cuantía de la cobertura y de la franquicia. La tabla muestra que estas variables también tienen distribuciones asimétricas a la derecha.
| Mínimo | Mediana | Media | Máximo | |
|---|---|---|---|---|
| Frecuencia | 0 | 0 | 1,109 | 263 |
| Severidad | 0 | 0 | 9.292 | 12.922.218 |
| Franquicia | 500 | 1.000 | 3.365 | 100.000 |
| Cobertura (miles) | 8,937 | 11.354 | 37.281 | 2.444.797 |
Código R de resumen de la frecuencia y coste de siniestros, franquicia y cobertura
El siguiente gráfico describe las variables de tarificación consideradas en este capítulo. Lo que deseamos que ocurra es que estas variables estén relacionadas de forma natural con la siniestralidad. Se puede obtener más información sobre dichas variables en Edward W. Frees, Lee, and Yang (2016). Para eliminar a asimetría, de ahora en adelante nos centraremos en las transformaciones logarítmicas de coberturas y franquicias.
** Descripción de las variables de tarificación **
\[ {\small \begin{matrix} \begin{array}{ l | l} \hline Variable & Descripción \\ \hline \text{EntityType} & \text{Variable cualitativa que toma uno de los seis valores siguientes: (Village, City,} \\ & ~~~~ \text{County, Misc, School, or Town)} \\ \text{LnCoverage} & \text{Total de cobertura del continente (edificio) y contenido, en logaritmo de millones de dólares}\\ \text{LnDeduct} & \text{Franquicia, en logaritmo de dólares} \\ \text{AlarmCredit} & \text{ Variable cualitativa que toma uno de los cuatro valores siguientes: (0, 5, 10, o 15)} \\ & ~~~~ \text{para alarmas de humo en habitación principal} \\ \text{NoClaimCredit} & \text{Variable binaria que indica ausencia de siniestros en los dos años anteriores} \\ \text{Fire5 } & \text{Variable binaria que indica que la categoría de incendios está por debajo de 5} \\ & ~~~~ \text{(El rango de las categorías de incendios va de 0 a 10)} \\ \hline \end{array} \end{matrix}} \]
Para tener una idea de la relación entre las variables de tarificación no continuas y los siniestros, la Tabla 1.5 presenta los resultados de siniestralidad cruzados con dichas variables categóricas. La Tabla 1.5 muestra una variación sustancial en la frecuencia de siniestros y su severidad media según el tipo de entidad. También se observa mayor frecuencia y gravedad según la variable \({\tt Fire5}\) variable y lo contrario para la variable \({\tt NoClaimCredit}\). La relación obtenida para la variable \({\tt Fire5}\) es contraintuitiva, ya que se esperarían cuantías más bajas para los asegurados en áreas con mejor protección pública (cuando el código de protección es cinco o menos). Naturalmente, existen otras variables que influyen en esta relación. En seguida veremos cómo afectan otras variables del fondo en el análisis de regresión multivariante, donde hallaremos un signo intuitivo y convincente (negativo) para el efecto de la variable \({\tt Fire5}\).
| Variable | Número de Pólizas | Frecuencia Siniestros | Coste Medio |
|---|---|---|---|
| EntityType | |||
| Village | 1.341 | 0,452 | 10.645 |
| City | 793 | 1,941 | 16.924 |
| County | 328 | 4,899 | 15.453 |
| Misc | 609 | 0,186 | 43.036 |
| School | 1.597 | 1,434 | 64.346 |
| Town | 971 | 0,103 | 19.831 |
| Fire | |||
| Fire5=0 | 2.508 | 0,502 | 13.935 |
| Fire5=1 | 3.131 | 1,596 | 41.421 |
| No Claims Credit | |||
| NoClaimCredit=0 | 3.786 | 1,501 | 31.365 |
| NoClaimCredit=1 | 1.853 | 0,310 | 30.499 |
| Total | 5.639 | 1,109 | 31.206 |
Resumen de siniestralidad según el tipo de entidad, la clase de incendio y la puntuación por ausencia de siniestros
La tabla 1.6 muestra la experiencia de siniestralidad según la puntuación de alarma. Se demuestra la dificultad de examinar las variables individualmente. Por ejemplo, cuando miramos la experiencia de todas las entidades, vemos que los titulares de pólizas sin puntuación de alarma tienen un coste medio de siniestros y una frecuencia más baja que los asegurados con mayor puntuación de alarma (un 15% de los asegurados cuentan con sistemas de vigilancia las 24h a través de una estación de bomberos o empresa de seguridad). En particular, cuando miramos el tipo de entidad “School,” la frecuencia es 0,422 y la severidad 25.523 si no hay puntuación de alarma, mientras que para el nivel de alarma más alto los valores ascienden a 2,008 y 85.140, respectivamente. Esto puede significar simplemente que las entidades con más siniestros son las que probablemente tengan tendencia a poner un sistema de alarma. En resumen, las tablas no examinan los efectos multivariantes; por ejemplo, la tabla 1.5 ignora cómo el efecto del tamaño (las cuantía de cobertura) afecta a la siniestralidad.
| Entidad Tipo | AC0 Sini. Frecuencia | AC0 Pro. Severidad | AC0 Núm. Pólizas | AC5 Sini. Frecuencia | AC5 Pro. Severidad | AC5 Núm. Polizas |
|---|---|---|---|---|---|---|
| Village | 0,326 | 11.078 | 829 | 0,278 | 8.086 | 54 |
| City | 0,893 | 7.576 | 244 | 2,077 | 4.150 | 13 |
| County | 2,140 | 16.013 | 50 | - | - | 1 |
| Misc | 0,117 | 15.122 | 386 | 0,278 | 13.064 | 18 |
| School | 0,422 | 25.523 | 294 | 0,410 | 14.575 | 122 |
| Town | 0,083 | 25.257 | 808 | 0,194 | 3.937 | 31 |
| Total | 0,318 | 15.118 | 2.611 | 0,431 | 10.762 | 239 |
| Entidad Tipo | AC10 Sini. Frequencia | AC10 Pro. Severidad | AC10 Núm. Pólizas | AC15 Sini. Frequencia | AC15 Pro. Severidad | AC15 Núm. Pólizas |
|---|---|---|---|---|---|---|
| Village | 0,500 | 8.792 | 50 | 0,725 | 10.544 | 408 |
| City | 1,258 | 8.625 | 31 | 2,485 | 20.470 | 505 |
| County | 2,125 | 11.688 | 8 | 5,513 | 15.476 | 269 |
| Misc | 0,077 | 3.923 | 26 | 0,341 | 87.021 | 179 |
| School | 0,488 | 11.597 | 168 | 2,008 | 85.140 | 1,013 |
| Town | 0,091 | 2.338 | 44 | 0,261 | 9.490 | 88 |
| Total | 0,517 | 10.194 | 327 | 2,093 | 41.458 | 2.462 |
Código R para el resumen de siniestralidad según el tipo de entidad y la categoría de puntuación de alarma
1.3.3 Operativa del fondo
Hasta ahora hemos visto las dos variables de siniestralidad del Fondo: una variable de recuento para el número de siniestros y una variable continua para el coste de las reclamaciones. También hemos introducido una variable de tarificación continua (cobertura); una variable cuantitativa discreta (franquicia en logarítmicos); dos variables de tarificación binarias (ausencia de siniestralidad y clase de incendio); y dos variables de tarificación categóricas (tipo de entidad y crédito de alarma). En los capítulos siguientes se explica cómo analizar y modelizar la distribución de dichas variables y sus relaciones. Antes de entrar en los detalles técnicos, pensemos a dónde queremos llegar. Las áreas funcionales de una compañía de seguros se describen en la Sección 1.2; veamos ahora cómo se aplicarían dichas áreas al contexto del fondo de propiedad que estamos analizando.
Inicio del seguro
Debido a que este es un fondo patrocinado por el gobierno, no tenemos que preocuparnos por seleccionar buenos riesgos o evitar malos riesgos; al fondo no se le permite denegar una solicitud de cobertura de una entidad gubernamental local. Por lo tanto, si no existe un proceso de suscripción, ¿qué hay que cobrar?
Podríamos mirar la experiencia más reciente en 2010, donde el total de todos los siniestros del fondos alcanzó la cifra de 28,16 millones de USD (\(= 1377 \text{ siniestros} \times 20452 \text{ coste medio}\)). Si lo dividimos entre 1.110 asegurados, eso sugiere una prima igual a 24.370 (\(\approx\) 28.160.000/1110). Sin embargo, 2010 fue un mal año; usando el mismo método, nuestra prima sería mucho menor según los datos de 2009. Este vaivén de las primas frustraría el propósito principal del fondo, que no es otro que fijar un precio constante que los administradores de propiedades locales puedan utilizar en sus presupuestos.
Tener un precio único para todos los asegurados es bueno, pero difícilmente parece justo. Por ejemplo, la tabla 1.5 sugiere que las escuelas tienen siniestros mucho más costosos que otras entidades y, por lo tanto, deberían pagar más. Sin embargo, hacer el cálculo entidad por entidad tampoco sería lo correcto. Por ejemplo, como vimos en la tabla 1.6 aquellas entidades con una puntuación de alarma del 15% (con un buen comportamiento, al tener los mejores sistemas de alarma) en realidad terminarían pagando más.
Entonces, parece que tenemos los datos para calcular primas adecuadas pero hay que profundizar en el análisis. Exploraremos estos aspectos más adelante en el Capítulo 7 sobre fundamentos de cálculo de primas. La selección de riesgos se introduce en el Capítulo 8 sobre clasificación de riesgos.
Renovación del seguro
Aunque el seguro de propiedad es típicamente un contrato de un año, la Table 1.3 sugiere que los asegurados tienden a renovar; esto es lo más habitual en los seguros generales. Para renovar a los asegurados, además de sus variables de tarificación, tenemos su historial de siniestralidad, que puede ser un buen predictor de los siniestros que van a producirse en el futuro. Por ejemplo, la tabla 1.5 muestra que los titulares de pólizas que no han sufrido ningún siniestro en los dos últimos años han tenido frecuencias de siniestralidad mucho más bajas que aquellos con al menos un accidente (0,310 frente a 1,501); una frecuencia predicha más baja generalmente resulta en una prima más baja. Por eso es normal que las aseguradoras utilicen variables como \({\tt NoClaimCredit}\) en su tarificación. Este tema se trata más a fondo en el Capítulo 9 sobre tarificación a través de la experiencia de sinistralidad.
Gestión de siniestros
Por supuesto, el protagonista de las pérdidas de 2010 fue el gran siniestro de más de 12 millones de dólares, casi la mitad de las reclamaciones de ese año. La pregunta es si esto podría haberse evitado o mitigado de alguna forma. ¿Hay maneras que el fondo se proteja contra sucesos con costes tan inusualmente elevados? Otra característica de lo ocurrido en 2010 fue la muy alta frecuencia de siniestros (239) para un único asegurado. Dado que solo hubo un total de 1377 reclamaciones de siniestro ese año, dicha frecuencia significa que un solo asegurado tuvo el 17,4% de los siniestros. Esto también indica que hay que realizar una adecuada gestión de siniestros, el tema del capítulo 10.
Reserva por pérdidas
En nuestro estudio de caso, solo observamos los resultados de un año de siniestros cerrados (lo contrario de los siniestros abiertos). Sin embargo, como en muchas otras líneas de seguro, las obligaciones derivadas de sucesos asegurados que afectan a los edificios tales como incendios, granizo y similares, no se conocen de inmediato y pueden llegar a concretarse más tarde, a lo largo del tiempo. En otras líneas de negocio, incluidas aquellas en las que hay lesiones a las personas, los siniestros requieren incluso mucho más tiempo hasta que llegan a cerrarse. El capítulo 11 presenta esta problemática y la reserva por pérdidas o provisiones, la disciplina que sirve para determinar cuánto debe reservar la compañía de seguros para cumplir con sus obligaciones.
1.4 Más Recursos y Colaboradores
Colaborador
- Edward W. (Jed) Frees, Universidad de Wisconsin-Madison, es el autor principal de la versión inicial de este capítulo. Correo electrónico: jfrees@bus.wisc.edu para comentarios sobre el capítulo y sugerencias de mejoras.
- Los revisores del capítulo incluyen: Yair Babad, Chunsheng Ban, Aaron Bruhn, Gordon Enderle, Hirokazu (Iwahiro) Iwasawa, Bell Ouelega.
- Traducción al español: Montserrat Guillen y Miguel Santolino (Universitat de Barcelona).
Este libro presenta las herramientas analíticas de datos de pérdidas que son más relevantes para los actuarios y otros analistas de riesgos financieros. También se presentan la terminología nueva de seguros; se pueden encontrar más términos en el NAIC Glossary (2018). Aquí hay algunas referencias citadas en el capítulo.
Notemos que la severidad promedio en la Tabla 1.3 difiere de la que se presenta en la Tabla 1.2. Esto ocurre porque en la primera se incluyen las pólizas que no han tenido siniestros mientras que en esta última los excluye. Esta es una distinción importante que se tratará en algunos apartados posteriores del texto.↩︎